- Published on
Actualizado el
Un RAG serio no responde: demuestra
- Authors

- Name
- Tonny Ruiz-Gijón
- @tonnyesp
Hay una forma bastante ingenua de pensar RAG:
meto todos mis documentos en una base vectorial, conecto un LLM potente y ya tengo una IA que responde sobre mi conocimiento interno.
Funciona para una demo.
Deja de funcionar en cuanto el conocimiento importa de verdad.
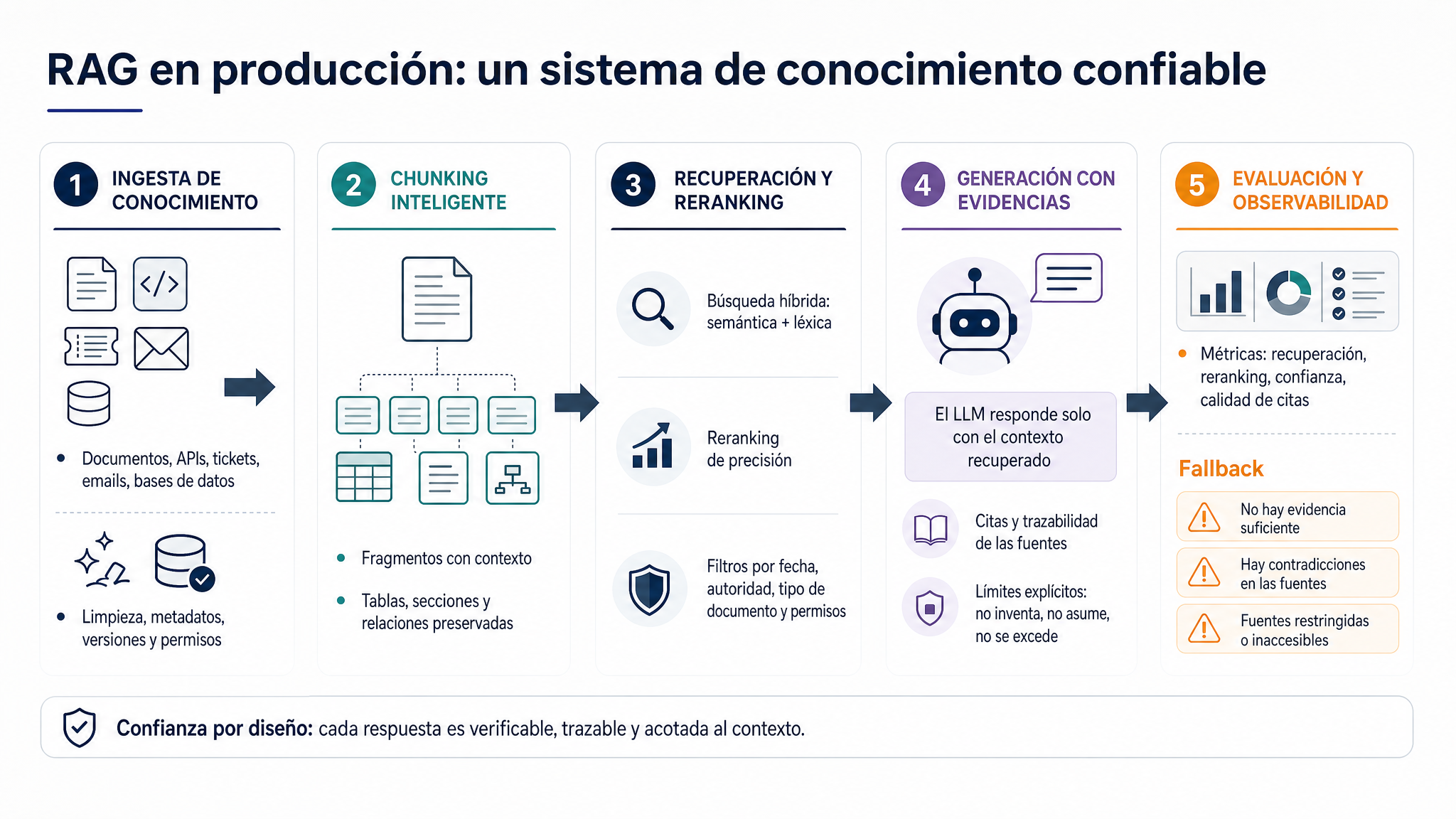
Si tienes diez documentos, puedes permitirte bastante improvisación. Si tienes diez millones, el problema cambia por completo. Ya no estás montando un chatbot con contexto. Estás construyendo un sistema de recuperación, confianza, generación, auditoría y evaluación.
Y ahí la pregunta importante no es “qué modelo responde mejor”.
La pregunta importante es otra:
¿qué puede demostrar este sistema con las fuentes que ha encontrado?
Esa diferencia parece pequeña, pero separa casi todos los RAG de juguete de los RAG que pueden vivir en producción.
El modelo no arregla una mala recuperación
Cada vez que aparece un modelo nuevo, una parte del sector vuelve a la misma tentación: pensar que el siguiente salto de inteligencia va a tapar las grietas del sistema.
En RAG pasa mucho.
Si el modelo alucina, cambiamos de modelo.
Si responde mal, aumentamos contexto.
Si se deja algo, metemos más chunks.
Si duda, hacemos el prompt más severo.
A veces ayuda. Pero no resuelve el problema de fondo.
Un modelo muy bueno sigue respondiendo mal si le das la evidencia equivocada. Una ventana de contexto enorme sigue siendo inútil si dentro has metido ruido. Una búsqueda semántica puede traer algo que “suena parecido” y aun así no sirve para contestar.
Esto conecta mucho con algo que ya he comentado otras veces sobre agentes: no siempre falta razonamiento; muchas veces falta contexto verificable.
Con RAG ocurre exactamente eso, pero a escala más incómoda.
El sistema no mejora sólo porque el modelo sea más listo. Mejora cuando es mejor encontrando, filtrando y justificando la información sobre la que el modelo va a trabajar.
El objetivo no es contestar. Es contestar con pruebas
Un chatbot normal intenta dar una respuesta útil.
Un RAG serio debería hacer algo más exigente: responder sólo cuando tiene base suficiente para hacerlo.
Eso implica varias obligaciones:
- encontrar fuentes relevantes,
- distinguir fuentes fiables de fuentes débiles,
- evitar documentos obsoletos,
- respetar permisos,
- citar exactamente de dónde sale cada afirmación importante,
- explicar incertidumbre cuando exista,
- y negarse a responder cuando la evidencia no alcanza.
Esto último cuesta más de lo que parece.
A muchos productos de IA les da pánico decir “no lo sé”. Parece una mala experiencia de usuario. Parece que el sistema falla.
Pero en conocimiento empresarial, legal, médico, financiero, técnico o de soporte crítico, una negativa honesta suele ser mucho mejor que una respuesta elegante y falsa.
La alucinación no aparece sólo cuando el modelo inventa de la nada. También aparece cuando el sistema le da contexto mediocre y luego lo empuja a sonar seguro.
Por eso, para mí, el principio base de un RAG en producción debería ser este:
si no puedes probarlo, no lo afirmes.
La ingesta ya forma parte del producto
El RAG empieza bastante antes de que el usuario haga una pregunta.
Empieza en la ingesta.
Y esta es una de las partes menos glamurosas, pero más determinantes.
En una organización real, los documentos no llegan limpios. Llegan como PDFs, HTML, Word, hojas de cálculo, wikis, emails, tickets, notas internas, páginas antiguas, exportaciones de APIs, imágenes escaneadas, tablas rotas y versiones duplicadas de lo mismo.
Algunos documentos están obsoletos.
Otros contradicen a documentos más nuevos.
Otros tienen permisos distintos.
Otros han sido copiados diez veces en sitios diferentes.
Otros sólo son fiables si entiendes el contexto en el que fueron escritos.
Si metes todo eso sin criterio en un índice vectorial, no tienes una base de conocimiento. Tienes un vertedero semántico.
La ingesta debería limpiar, normalizar y enriquecer el corpus antes de indexarlo:
- deduplicar documentos,
- conservar versiones,
- extraer título, autor, fecha, área, tipo de documento y fuente,
- detectar idioma,
- separar tablas, notas y anexos cuando haga falta,
- mantener permisos,
- marcar nivel de confianza,
- y saber qué documento sustituye a cuál.
La frescura importa mucho.
Una política interna de 2022 puede ser perfectamente recuperable y perfectamente incorrecta. Si el sistema no sabe que existe una versión de 2026, citará basura con mucha seguridad.
Este es uno de los errores clásicos: tratar la ingesta como “carga de datos”.
No lo es.
Es preparación de conocimiento.
Chunking: cortar mal también es perder conocimiento
Después viene otra decisión aburrida que rompe muchísimos sistemas: cómo troceas los documentos.
El chunking parece un detalle técnico. No lo es.
Si cortas demasiado pequeño, pierdes contexto. El sistema recupera frases sueltas que no bastan para entender la respuesta.
Si cortas demasiado grande, metes ruido. El modelo recibe páginas enteras donde sólo dos párrafos importan.
Si cortas sin respetar estructura, rompes tablas, listas, títulos, secciones legales o pasos de un procedimiento.
No hay una regla universal.
Un contrato, una documentación técnica, una política de RRHH, una FAQ y un ticket de soporte no deberían trocearse igual.
En producción, el chunking debería respetar la forma del documento:
- secciones y subsecciones,
- encabezados,
- tablas,
- bloques de código,
- listas de pasos,
- notas al pie,
- y relaciones entre fragmentos.
También conviene guardar referencias al documento padre. Muchas respuestas necesitan recuperar no sólo el chunk exacto, sino el contexto alrededor: sección completa, versión, página, fecha o documento relacionado.
Un buen RAG no indexa texto como quien pasa una trituradora.
Indexa unidades de evidencia.
La búsqueda semántica sola no basta
Los embeddings son muy útiles.
Permiten que el sistema entienda que “plazo de reembolso”, “ventana para presentar gastos” y “expense claim deadline” pueden apuntar al mismo asunto.
Pero la búsqueda semántica tiene límites claros.
Puede fallar con:
- códigos de error,
- nombres propios,
- referencias legales,
- números de contrato,
- IDs de producto,
- campos de API,
- versiones concretas,
- siglas internas,
- y términos raros que no deberían ser aproximados.
Ahí una búsqueda léxica clásica sigue siendo muy valiosa.
BM25 no es moderno ni sexy, pero encuentra palabras exactas muy bien. Y en muchos sistemas reales eso sigue siendo imprescindible.
Por eso, a escala seria, lo normal no debería ser elegir entre búsqueda vectorial o búsqueda por keywords.
Lo razonable es combinar ambas.
La búsqueda híbrida permite que el sistema capture significado amplio sin perder precisión exacta. Recupera documentos por similitud semántica, pero también por coincidencia textual cuando el usuario pregunta por algo específico.
En RAG, como en muchas partes de los agentes, la solución buena no suele ser una pieza mágica.
Suele ser composición.
Primero recuperas candidatos. Luego decides cuáles valen
Con millones de documentos no puedes comparar cada pregunta contra todo el corpus de forma profunda.
Necesitas una primera fase rápida que reduzca el espacio de búsqueda.
Ahí entran los índices aproximados y la recuperación de candidatos. El sistema trae, por ejemplo, los 100, 200 o 500 fragmentos que parecen más prometedores.
Pero esa primera lista no debería ir directamente al modelo.
Ese es otro fallo típico.
La recuperación inicial busca velocidad. No garantiza que el primer resultado sea la mejor evidencia. Sólo dice: “esto merece mirarse”.
Después hace falta una fase más cara y más precisa: reranking.
Un reranker compara la pregunta y cada candidato de forma más directa. No se limita a mirar si los vectores están cerca. Intenta estimar si ese fragmento realmente ayuda a responder esa pregunta.
La diferencia entre “relacionado” y “útil para contestar” es enorme.
Un documento puede hablar del mismo tema y no contener la respuesta. Puede compartir vocabulario y estar diciendo justo lo contrario. Puede ser una introducción general cuando necesitas una cláusula exacta.
El reranking es una de esas capas que no lucen en una demo, pero cambian mucho la calidad en producción.
Relevancia no es confianza
Incluso cuando recuperas un fragmento muy relevante, todavía falta una pregunta:
¿deberíamos confiar en esta fuente?
No todo lo relevante es fiable.
Una nota antigua en Slack puede mencionar justo el procedimiento que busca el usuario. Pero quizá el procedimiento cambió hace seis meses.
Un ticket puede describir un workaround real. Pero quizá nunca fue aprobado.
Una página de una wiki puede estar muy bien posicionada. Pero quizá nadie la revisa desde hace años.
Por eso un RAG serio necesita puntuar también la confianza de las fuentes.
Esa confianza puede depender de varias señales:
- fecha de actualización,
- autoridad de la fuente,
- tipo de documento,
- propietario,
- estado de aprobación,
- consistencia con otras fuentes,
- calidad de metadatos,
- historial de versiones,
- y permisos del usuario.
Un documento oficial actualizado ayer debería pesar más que una conversación informal de hace tres años.
Una respuesta apoyada por varias fuentes independientes debería ser más fuerte que una respuesta sostenida por un único fragmento dudoso.
Y si dos fuentes se contradicen, el sistema no debería mezclar ambas y producir una síntesis bonita. Debería detectar el conflicto, priorizar la fuente más autorizada o decir que hay inconsistencia.
Este es uno de los puntos donde se nota si estás construyendo un juguete o un producto.
El juguete busca texto parecido.
El producto pregunta si esa evidencia merece gobernar la respuesta.
La generación tiene que estar encerrada dentro de la evidencia
Cuando ya tienes fuentes seleccionadas, entra el LLM.
Pero no debería entrar como “cerebro general”.
Debería entrar como capa de síntesis.
Su trabajo no es recordar, completar ni adornar. Su trabajo es leer la evidencia disponible y construir una respuesta comprensible sin salirse de ella.
Eso exige instrucciones muy explícitas:
- responde sólo con el contexto recuperado,
- no uses conocimiento externo,
- no rellenes huecos,
- no conviertas inferencias en hechos,
- cita las fuentes usadas,
- y si no hay evidencia suficiente, dilo.
Para casos delicados, incluso iría más lejos: cada afirmación importante debería tener una cita asociada.
No basta con poner tres fuentes al final de la respuesta como decoración.
La trazabilidad tiene que estar al nivel de la afirmación.
Si dices “el plazo es de 30 días”, quiero saber de qué documento, versión, página o fragmento sale ese dato. Si dices “esto no aplica a empleados externos”, quiero poder verificarlo.
Ahí el modelo deja de ser un oráculo y se convierte en un redactor bajo contrato.
Puede escribir mejor que el sistema de búsqueda. Puede resumir. Puede estructurar. Puede adaptar el tono.
Pero no puede inventarse jurisdicción.
Las citas no son adorno. Son interfaz de depuración
Muchas veces se habla de citas como una forma de generar confianza en el usuario.
Lo son.
Pero también son una herramienta brutal de ingeniería.
Cuando una respuesta sale mal, las citas permiten saber dónde falló el pipeline.
Puede haber fallado la recuperación inicial.
Puede que BM25 encontrara el documento correcto y la búsqueda vectorial no.
Puede que el reranker hundiera la fuente buena.
Puede que el sistema de confianza priorizara un documento obsoleto.
Puede que el LLM leyera mal una tabla.
Puede que el chunk no tuviera suficiente contexto alrededor.
Sin citas y trazas, todo eso se convierte en una discusión subjetiva sobre “la IA ha respondido mal”.
Con citas, puedes abrir la caja y ver el camino exacto que llevó a esa respuesta.
En sistemas de conocimiento, eso cambia muchísimo.
No sólo mejora la confianza. Mejora la capacidad de mantenimiento.
A veces la mejor respuesta es no responder
Un RAG de producción necesita una capa de fallback.
Si la evidencia es débil, contradictoria, antigua o insuficiente, el sistema debería frenar.
No pasa nada por decir:
No he encontrado evidencia suficiente para responder con seguridad.
O:
Hay documentos relevantes, pero se contradicen entre sí. La fuente más reciente dice X y una fuente antigua dice Y.
O:
No tengo acceso a documentos que permitan contestar esta pregunta.
Eso no es una mala UX.
Es una UX honesta.
La tolerancia al riesgo depende del dominio. Un asistente de soporte general puede permitirse más flexibilidad. Un sistema legal, médico, financiero o de compliance necesita umbrales mucho más duros.
Aquí vuelve una idea que me interesa mucho en agentes: la autonomía útil no consiste en dejar que el sistema haga más cosas siempre. Consiste en diseñar cuándo debe actuar, cuándo debe pedir ayuda y cuándo debe negarse.
La contención también es producto.
Sin evaluación continua, todo esto son vibes
Un RAG no se termina cuando indexas documentos y pasan tres pruebas manuales.
El corpus cambia.
Los usuarios cambian.
Los modelos cambian.
Las políticas internas cambian.
La forma de preguntar cambia.
Los índices envejecen.
Las estrategias de chunking dejan de ser buenas.
Por eso necesitas evaluación continua.
No sólo evaluación de la respuesta final. También de cada capa:
- si la fuente correcta aparece entre los candidatos,
- si el reranker la sube lo suficiente,
- si el filtro de confianza elimina basura,
- si el modelo cita bien,
- si rechaza cuando debería rechazar,
- si distingue documentos parecidos,
- y si mantiene permisos.
Las queries adversariales son especialmente útiles.
Preguntas que fuerzan contradicciones. Preguntas con documentos obsoletos. Preguntas donde la respuesta no existe. Preguntas con códigos exactos. Preguntas donde dos áreas usan la misma palabra para cosas distintas.
Ahí se ve si el sistema está razonando sobre evidencia o simplemente intentando quedar bien.
Esto se parece mucho a lo que pasa con agentes largos: si no tienes evaluación separada y trazable, el sistema tiende a felicitarse demasiado pronto.
Ya lo decía al hablar de arneses para tareas largas: el problema no es sólo que el agente falle, sino que no siempre sabe detectar que ha fallado.
Con RAG pasa igual.
Caché y memoria, sí. Pero sin convertirlas en fuente de verdad
A esta escala, la latencia y el coste importan.
No puedes recalcular todo siempre desde cero si hay muchas preguntas repetidas o patrones muy parecidos.
Cachear consultas, resultados de recuperación, rankings o respuestas validadas puede ahorrar bastante.
Pero hay que hacerlo con cuidado.
Una respuesta cacheada puede ser insegura si:
- el usuario actual tiene permisos distintos,
- el documento cambió,
- apareció una versión nueva,
- el contexto de negocio ya no aplica,
- o la respuesta dependía de una sesión anterior.
La memoria también puede ayudar, sobre todo para personalizar el flujo o conservar preferencias del usuario.
Pero no debería competir con la evidencia recuperada.
La memoria puede decir “este usuario trabaja en el área X” o “prefiere respuestas breves”.
No debería decir “la política de gastos es esta” si no se acaba de recuperar y validar una fuente que lo sostenga.
La fuente de verdad tiene que seguir siendo el corpus gobernado, no el recuerdo cómodo del sistema.
Observabilidad o superstición
En RAG, la observabilidad no es un extra de plataforma.
Es la diferencia entre operar un sistema y practicar superstición.
Deberías poder ver:
- consulta original,
- query reescrita si existe,
- resultados léxicos,
- resultados vectoriales,
- candidatos iniciales,
- puntuaciones del reranker,
- señales de confianza,
- chunks seleccionados,
- chunks descartados,
- prompt final,
- citas usadas,
- latencia,
- coste,
- tokens,
- y respuesta final.
Sin eso, cada fallo se vuelve una investigación artesanal.
Y en cuanto el sistema escala, la artesanía no basta.
Necesitas trazas, dashboards, muestras revisables, métricas de recuperación, métricas de rechazo, análisis de alucinación y feedback real de usuarios.
Si no puedes explicar por qué el sistema respondió algo, probablemente no deberías ponerlo en un flujo crítico.
Mi checklist mental para un RAG serio
Si tuviera que revisar un RAG con millones de documentos, miraría esto antes de discutir qué modelo genera la respuesta:
Corpus
- ¿Los documentos están deduplicados?
- ¿Hay versiones y frescura?
- ¿Se respetan permisos?
- ¿Existe metadata útil?
- ¿Sabemos qué fuentes son más autorizadas?
Indexación
- ¿El chunking respeta la estructura del documento?
- ¿Se conservan referencias al documento padre?
- ¿Hay estrategia distinta para tablas, código, FAQs o políticas?
- ¿Se reindexa cuando cambia la fuente?
Recuperación
- ¿Hay búsqueda híbrida?
- ¿Se miden recall y precisión?
- ¿Se separa recuperación rápida de reranking?
- ¿Se evalúan consultas exactas y semánticas?
Confianza
- ¿Se puntúa autoridad, frescura y consistencia?
- ¿Se detectan contradicciones?
- ¿Se filtran fuentes débiles?
- ¿Hay umbrales para negarse a responder?
Generación
- ¿El modelo está limitado al contexto recuperado?
- ¿Cita afirmaciones importantes?
- ¿Distingue hechos de inferencias?
- ¿Puede decir “no hay evidencia suficiente”?
Operación
- ¿Hay trazas completas?
- ¿Hay evaluación continua?
- ¿Se revisan fallos reales?
- ¿La caché respeta permisos y frescura?
Si varias de estas respuestas son “no”, cambiar de modelo probablemente no va a salvar el producto.
Idea final
Un RAG serio no es un LLM con una base vectorial al lado.
Es un sistema de conocimiento.
Y un sistema de conocimiento no se mide por lo convincente que suena, sino por lo bien que encuentra evidencia, la entiende, la prioriza, la cita y se calla cuando no tiene base suficiente.
La calidad no está sólo en la respuesta final.
Está en todo el camino previo:
- ingesta,
- chunking,
- búsqueda híbrida,
- recuperación rápida,
- reranking,
- confianza de fuentes,
- generación restringida,
- citas,
- fallback,
- evaluación,
- caché,
- memoria,
- y observabilidad.
Por eso, cuando alguien dice que quiere un RAG con “cero alucinaciones”, yo no empezaría preguntando qué modelo va a usar.
Empezaría preguntando algo bastante menos vistoso:
¿qué hace tu sistema cuando no puede demostrar la respuesta?
Porque ahí se ve si estás construyendo una demo que responde mucho o un producto que merece confianza.